











Succinct 数据结构是一类使用非常少量的空间来存储数据的结构。与压缩不同的是,Succinct在减少空间存储开销的同时可以进行非常高效的访问操作。
Jacobson的这篇论文提出了针对树和图的Succinct数据结构。树这部分我看到@一只硬核少年在Space-efficient Static Trees and Graphs这篇文章中做了非常详细的解读。
图的部分这两天边读边做了些笔记,发出来和大家分享一下。如果有错漏的地方欢迎指正。
目录
4. 线性空间复杂度的可平面图(Planar Graph)
Turan等人提出一种使用12个bit表示一个结点的平面图存储方法,证明平面图可以以线性空间复杂度存储;Kannan等人基于Nash-Williams定理,将可平面图分解成三个边不相接的生成树。
论文中提出一种方法,将可平面图分解成页(pages),从而在线性空间复杂度的表示之上实现高效的搜索和邻接判定。
首先介绍一下括号平衡器(Parentheses Blancer)这个结构。
4.1 括号平衡问题
问题定义:
给定一个由n个括号构成的静态平衡字符串(静态指字符串不会改变),通过构建一个空间占用O(n)的字典来优化下面这个操作:
- 在字符串中找到与位置p上的左括号
(匹配的右括号) - 反过来,在位置p上找到与右括号
)匹配的左括号(。
这个问题可以简化为给定左括号找匹配的右括号的问题,因为两种操作是对称的。
首先将字符串分割为 log n 大小的等长块,每个块从 1 开始编号,有以下定义:
- 括号p被称为远括号(Far Parenthesis),当且仅当p的匹配括号位于其自己所在的块之外。
- 远括号被称为先锋括号(Pionneer),当且仅当其匹配括号位于字符串中前一个远括号所在块的不同块中。
维护以下两个数据结构:
- 一个大小为
n用于记录第i个括号是否为先锋括号的位图; - 位图对应的rank表;
- 一个记录每个先锋括号的匹配括号所在块号的表格;
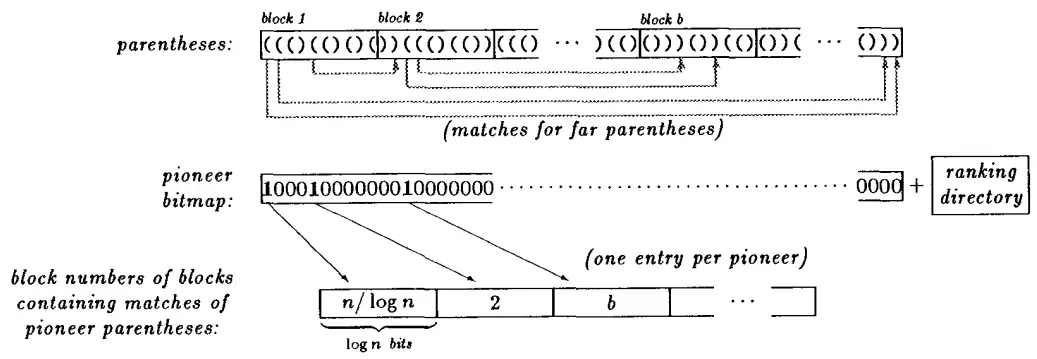
如果下标 p 的括号不是远括号,可以在所属块中做上界为 log n 线性扫描。否则可以通过索引计算得到匹配括号 q 所在的块号:
- 计算下标为
p的括号在先锋括号位图中的rank值rank(p); - 块号表第
rank(p)个元素即q所在的块号。
为了在块中更快地找到 q 的准确位置,另外维护一个记录每个块的嵌套深度(Nesting Depth:字符串前缀中开括号数量超过闭括号数量的总和)的表。

在这些索引的帮助下我们可以以 O(log n) 时间复杂度搜索匹配括号,而且位图、rank表以及嵌套深度表这三个辅助数据结构增加的额外空间开销仅仅是 2n+o(n) 个bits。
块号表空间开销和先锋括号的数量有关。每个块号长度为 log n 个bits,当先锋括号的数量超过 n/log n 时,块号表的空间开销将超过 O(n) 。但下面的证明说明在一个划分为 b 个块的字符串中,先锋括号的数量不会超过 2b-3:
证明如下:
- 首先,假设我们构建一个图,图中的每个节点代表字符串的一个块。将这些节点按顺序排成一条直线,对应着块的顺序。如果一个块中有一个远括号指向另一个块,就在这两个节点之间添加一条边。
- 在这样构建的图中,边的数量至少等于字符串中先锋括号的数量,因为每个先锋括号可以映射到不同的边上。
- 由于这个括号字符串是平衡的,意味着任意两个块之间的括号匹配是正确的,因此在图中没有边会交叉。
- 这样得到的图是一个外平面图(outer-planar),也就是说可以在平面上嵌入这个图,使得所有的节点都在一个面上。
- 外平面图的一个已知性质是,其边的数量最多为2b – 3。
由于块号表中的每个元素都只有 lg n 个bit长,因此整张表的长度最多 [2(n/lg n)-3]*lg n=2n+o(n) 个bit.
4.2 有界页数图
在图论中,有界页数图(Bounded pagenumber graphs) 是一种比平面图抽象程度更高的图,书嵌入是图的平面嵌入到书嵌入的推广。
定义一:图的k页书嵌入(k-page book embedding):
给定一个图G=<V, E>,图的k页书嵌入是点集V的一个打印排列(点在书脊线上按不同顺序排列的一个排序),该排列对应的一种将
E划归到k页中的划分,同一页中的任意两边不能相交,且所有划分出的页共享同一个打印排列。(详细请看:[4])
定义二:页数/书厚度(pagenumber/book-thickness):
图的所有书嵌入中最小的页数
设��是所有页数上界为 k 的图集合,给定任意图 �∈��以及一个该图的k页嵌入,下面会展示以一个在图G中访问邻居和判断是否邻接的方法。
对于一个n个结点的图G,每次操作只需要访问 O(log n) 个比特,图的表示使用的比特数是 O(kn) .
简单起见下面先讲解单页图(外平面图)的线性空间表示方法,然后再进行扩展。
4.2.1 单页图的线性空间表示法
单页图中所有边都可以放到沿着某个点排列构成的书脊线的一侧,且任何两条边都不相交。
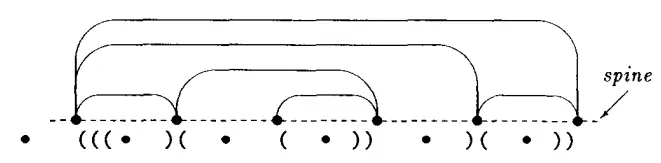
对于一个有n个结点的单页图,每个结点用一个 · 表示。单页图中的每条边 <u, v> ,在 第(u+1)
个结点前插入一个 ( 符号,第 v 个结点前插入一个 ) 符号。可以发现这样插入左右括号以后就形成了一个平衡括号串,这个平衡括号串包含 · , ( 以及 ) 三种符号。其中结点数量是 n 个,左右括号最多分别有 2n-3 个。第 m 和 m+1 个结点之间的所有括号都对应节点 m 的一条边。
现在将这个3符号串编码成两个位串:
- 标记所有结点所在位置的位图,称之为结点位图(node-map);
- 删除结点符号后, 用
0表示左括号,1表示右括号的位串。
两个比特串加起来总共最多需要比特数:

这两个位串是图的线性空间表示的关键。
接下来构造两个辅助结构:
- 括号串的匹配器(matcher for the parentheses string)
- 结点位图的
rank/select和rank0/select0表
这两个辅助结构会增加额外的空间开销,但总开销不会超过 O(n) .
结点在书脊线上的打印顺序可以作为结点的索引下标,括号字符串中的索引下标可以作为边的索引下标。
4.2.2 查找与邻接判断
有了上面这些数据结构,我们在图G中进行查找比起前面的括号匹配要稍微麻烦一点。
图G中的每条边都和一对括号对应,沿着一条边走等价于给定左括号的下标查找对应的右括号。
为了方便我们定义两个函数:

node-to-edge:给定结点编号m,求该从结点出去的第一条边的下标;edge-to-node:给定括号串中的一个边下标,找到这条边对应的顶点编号.
- 访问结点
m邻居结点的算法如下:
e = node-to-edge(m)
while(edge-to-node(e) == m) {
next_node = paren-match(e) //找到与e匹配的括号位置
visit(edge-to-node(next_node))
e = e+1
}这个算法只需要常数次数的 rank/select 以及括号匹配操作,因此每次访问邻居只需要 O(log n) 次比特访问。
2. 邻接判断(给定结点 u 和 v ,判断是否存在一条边 <u, v> 连接这两个节点)的操作也可以以 O(log n) 的时间复杂度进行。详细过程在作者的博士论文[2]中。
4.2.3 多页图
将单页图的线性空间表示法扩展到多页图的方法非常简单:
- 如果一个图G是
k-page图,将k页分别作为一个单页图表示即可。 - 要访问给定节点
m的所有邻居只需要分别在k页中执行上面的邻居访问算法即可,判断邻接也是类似。
可见,任何 k-page 图都可以在 O(kn) 空间复杂度下表示,以 O(klog n) 的时间复杂度搜索和判断邻接。
Yannakakis[3]提出过一个线性时间复杂度的算法,可将任意平面图嵌入到4页以内的书中。
本论文展示了任意类型的有界页数图都可以通过线性空间表示,这个结论也适用于平面图。
参考资料
[1] Jacobson, G. (1989, October). Space-efficient static trees and graphs. In 30th annual symposium on foundations of computer science (pp. 549-554). IEEE Computer Society.
[2] Jacobson, G. J. (1988). Succinct static data structures. Carnegie Mellon University.(PDF)
[3] Yannakakis, M. (1986, November). Four pages are necessary and sufficient for planar graphs. In Proceedings of the eighteenth annual ACM symposium on theory of computing (pp. 104-108).


